
Introduction to numpy#
Note
This material is mostly adapted from the following resources:
Numpy is the fundamental package for scientific computing with Python. NumPy is the standard Python library used for working with arrays (i.e., vectors & matrices), linear algebra, and other numerical computations.
Website: https://numpy.org/
GitHub: numpy/numpy
Note
Documentation for this package is available at https://numpy.org/doc/stable/index.html.
Note
If you have not yet set up Python on your computer, you can execute this tutorial in your browser via Google Colab. Click on the rocket in the top right corner and launch “Colab”. If that doesn’t work download the .ipynb file and import it in Google Colab
Then install numpy by executing the following command in a Jupyter cell at the top of the notebook.
!pip install numpy
Importing a Package#
This will be our first experience with importing a package.
Usually we import numpy with the alias np.
import numpy as np
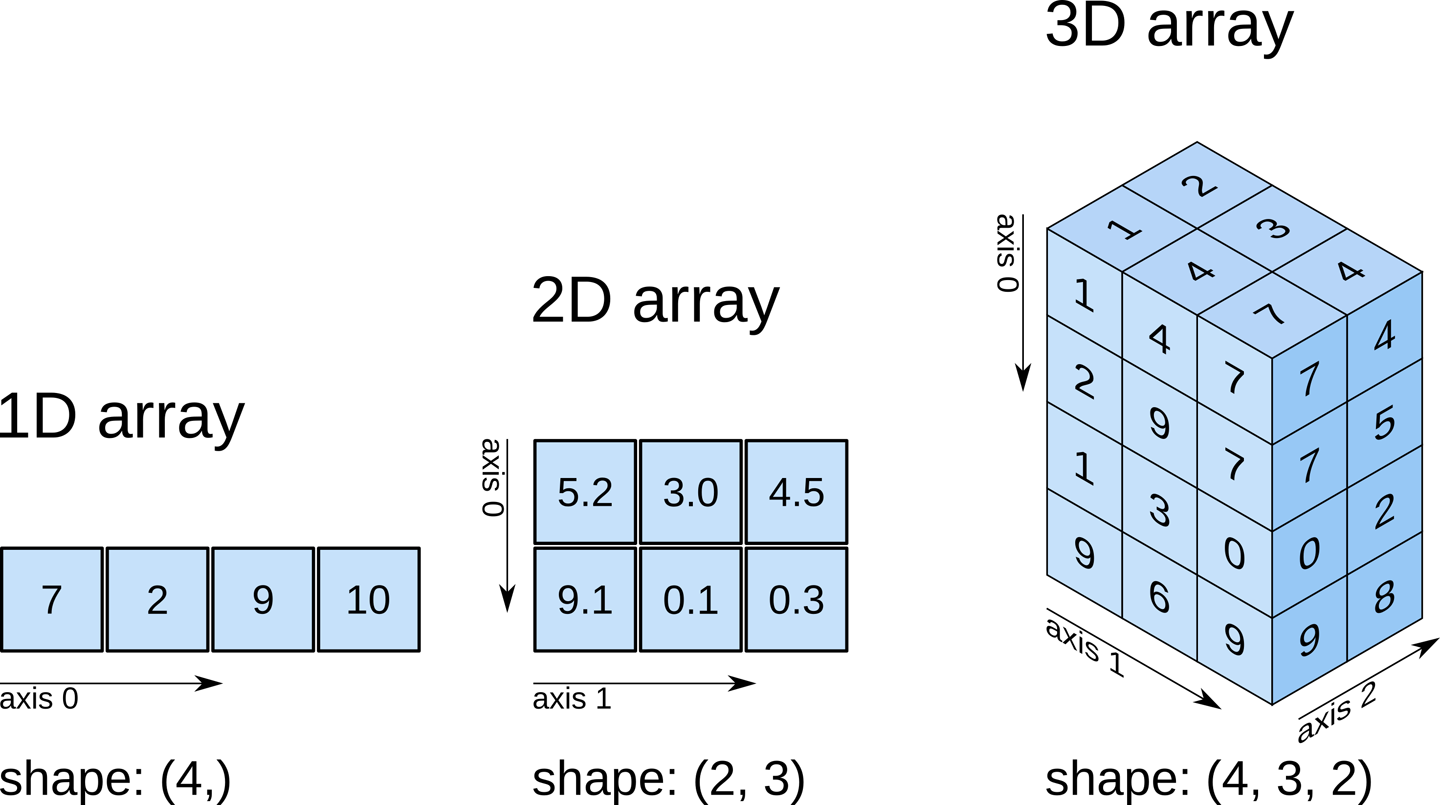
NDArrays#
NDarrays (short for n-dimensional arrays) are a key data structure in numpy. NDarrays are similar to Python lists, but they allow fast, efficient computations on large arrays and matrices of numerical data. NDarrays can have any number of dimensions, and are used for a wide range of numerical and scientific computing tasks, including linear algebra, statistical analysis, and image processing.
Thus, the main differences between a numpy array and a list are the following:
numpyarrays can have N dimensions (while lists only have 1)numpyarrays hold values of the same datatype (e.g.int,float), while lists can contain anything.numpyoptimizes numerical operations on arrays. Numpy is fast!
# create an array from a list
a = np.array([9, 0, 2, 1, 0])
Note
If you’re in Jupyter, you can use <shift> + <tab> to inspect a function.
# find out the datatype
a.dtype
dtype('int64')
# find out the shape
a.shape
(5,)
# another array with a different datatype and shape
b = np.array([[5, 3, 1, 9], [9, 2, 3, 0]], dtype=np.float64)
# check dtype
b.dtype
dtype('float64')
# check shape
b.shape
(2, 4)
Array Creation#
There are lots of ways to create arrays.
np.zeros((4, 4))
array([[0., 0., 0., 0.],
[0., 0., 0., 0.],
[0., 0., 0., 0.],
[0., 0., 0., 0.]])
np.ones((2, 2, 3))
array([[[1., 1., 1.],
[1., 1., 1.]],
[[1., 1., 1.],
[1., 1., 1.]]])
np.full((3, 2), np.pi)
array([[3.14159265, 3.14159265],
[3.14159265, 3.14159265],
[3.14159265, 3.14159265]])
np.random.rand(5, 2)
array([[0.16759168, 0.1275737 ],
[0.84136607, 0.35864635],
[0.26396999, 0.99950835],
[0.32993925, 0.54246117],
[0.46186264, 0.62139472]])
np.arange(10)
array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9])
np.arange(2, 4, 0.25)
array([2. , 2.25, 2.5 , 2.75, 3. , 3.25, 3.5 , 3.75])
A frequent need is to generate an array of N numbers, evenly spaced between two values. That is what linspace is for.
np.linspace(2, 4, 20)
array([2. , 2.10526316, 2.21052632, 2.31578947, 2.42105263,
2.52631579, 2.63157895, 2.73684211, 2.84210526, 2.94736842,
3.05263158, 3.15789474, 3.26315789, 3.36842105, 3.47368421,
3.57894737, 3.68421053, 3.78947368, 3.89473684, 4. ])
Numpy also has some utilities for helping us generate multi-dimensional arrays.
For instance, meshgrid creates 2D arrays out of a combination of 1D arrays.
x = np.linspace(-2 * np.pi, 2 * np.pi, 5)
y = np.linspace(-np.pi, np.pi, 4)
xx, yy = np.meshgrid(x, y)
xx.shape, yy.shape
((4, 5), (4, 5))
yy
array([[-3.14159265, -3.14159265, -3.14159265, -3.14159265, -3.14159265],
[-1.04719755, -1.04719755, -1.04719755, -1.04719755, -1.04719755],
[ 1.04719755, 1.04719755, 1.04719755, 1.04719755, 1.04719755],
[ 3.14159265, 3.14159265, 3.14159265, 3.14159265, 3.14159265]])
xx
array([[-6.28318531, -3.14159265, 0. , 3.14159265, 6.28318531],
[-6.28318531, -3.14159265, 0. , 3.14159265, 6.28318531],
[-6.28318531, -3.14159265, 0. , 3.14159265, 6.28318531],
[-6.28318531, -3.14159265, 0. , 3.14159265, 6.28318531]])
Indexing#
Basic indexing in numpy is similar to lists.
# get some individual elements of xx
xx[3, 4]
np.float64(6.283185307179586)
# get some whole rows
xx[0]
array([-6.28318531, -3.14159265, 0. , 3.14159265, 6.28318531])
# get some whole columns
xx[:, -1]
array([6.28318531, 6.28318531, 6.28318531, 6.28318531])
# get some ranges (also called slicing)
xx[0:2, 3:5]
array([[3.14159265, 6.28318531],
[3.14159265, 6.28318531]])
Broadcasting#
Not all the arrays we want to work with will have the same size!
Broadcasting is a powerful feature in numpy that allows you to perform operations on arrays of different shapes and sizes. It automatically expands the smaller array to match the dimensions of the larger array, without actually making copies of the data, so that element-wise operations can be performed. This is done by following a set of rules that determine how the shapes of the arrays align.
Broadcasting allows you to vectorize operations and avoid explicit loops, leading to more concise and efficient code. It’s particularly useful when working with large data sets, as it helps optimize memory usage and computational speed.
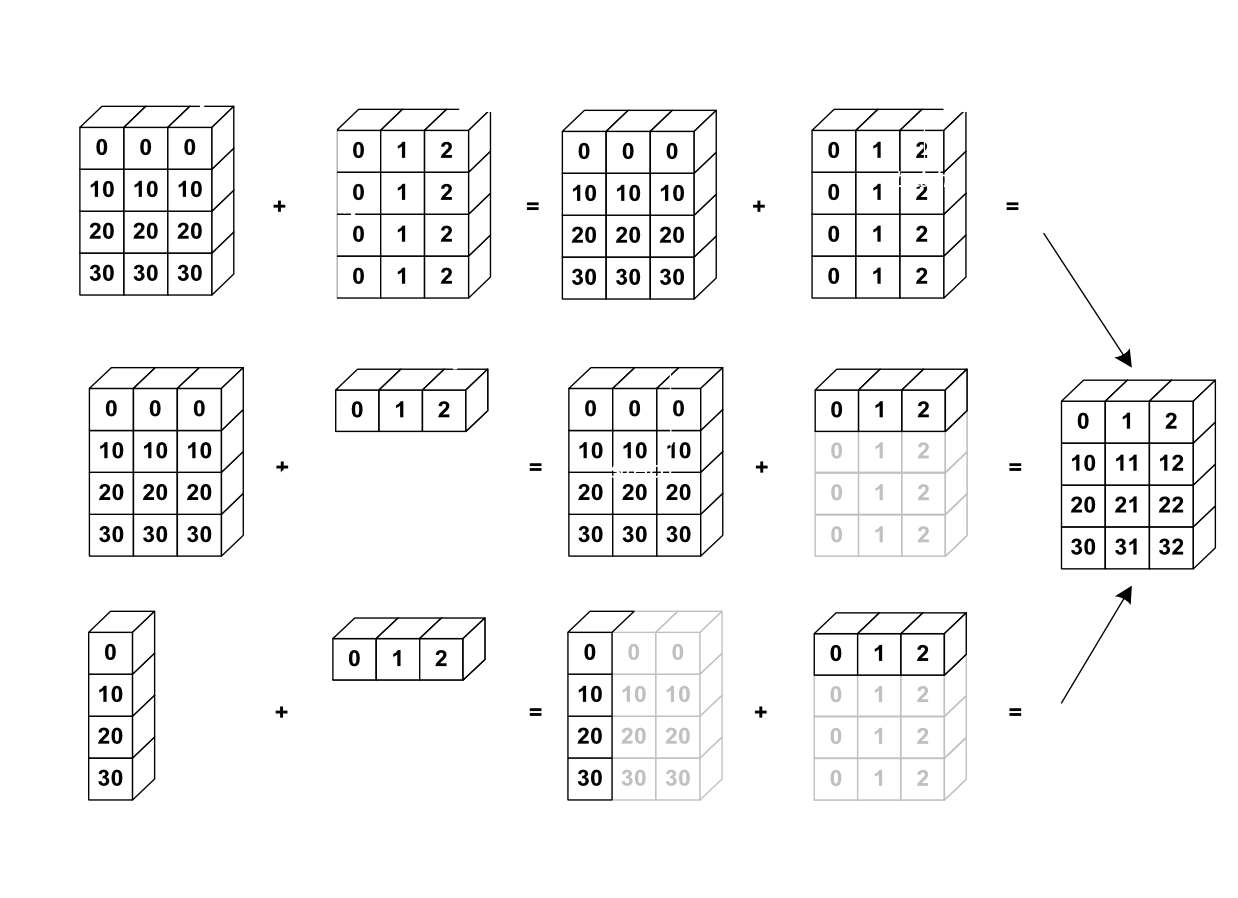
Dimensions are automatically aligned starting with the last dimension. If the last two dimensions have the same length, then the two arrays can be broadcast.
f = np.sin(xx) * np.cos(0.5 * yy)
print(f.shape, x.shape)
(4, 5) (5,)
g = f * x
print(g.shape)
(4, 5)
Reduction Operations#
In data science, we usually start with a lot of data and want to reduce it down in order to make plots of summary tables.
There are many different reduction operations. The table below lists the most common functions:
Reduction Operation |
Description |
|---|---|
|
Computes the sum of array elements over a given axis. |
|
Computes the arithmetic mean along a specified axis. |
|
Computes the minimum value along a specified axis. |
|
Computes the maximum value along a specified axis. |
|
Computes the product of array elements over a given axis. |
|
Computes the standard deviation along a specified axis. |
|
Computes the variance along a specified axis. |
# sum
g.sum()
np.float64(-3.9982744542688894e-15)
# mean
g.mean()
np.float64(-1.9991372271344446e-16)
# standard deviation
g.std()
np.float64(5.809358098232775e-16)
A key property of numpy reductions is the ability to operate on just one axis.
# apply on just one axis
g_ymean = g.mean(axis=0)
g_xmean = g.mean(axis=1)
Exercises#
Import numpy under the alias np.
Show code cell content
import numpy as np
Create the following arrays:
Create an array of 5 zeros.
Create an array of 10 ones.
Create an array of 5 \(\pi\) values.
Create an array of the integers 1 to 20.
Create a 5 x 5 matrix of ones with a dtype
int.
Show code cell content
np.zeros(5)
array([0., 0., 0., 0., 0.])
Show code cell content
np.ones(10)
array([1., 1., 1., 1., 1., 1., 1., 1., 1., 1.])
Show code cell content
np.full(5, np.pi)
array([3.14159265, 3.14159265, 3.14159265, 3.14159265, 3.14159265])
Show code cell content
np.arange(1, 21)
array([ 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17,
18, 19, 20])
Show code cell content
np.ones((5, 5), dtype=np.int8)
array([[1, 1, 1, 1, 1],
[1, 1, 1, 1, 1],
[1, 1, 1, 1, 1],
[1, 1, 1, 1, 1],
[1, 1, 1, 1, 1]], dtype=int8)
Create a 3D matrix of 3 x 3 x 3 full of random numbers drawn from a standard normal distribution (hint: np.random.randn())
Show code cell content
np.random.randn(3, 3, 3)
array([[[ 1.42759815, 1.41913641, 0.77430445],
[ 0.82939175, 0.2932272 , 0.00217674],
[-0.4020654 , 0.21454196, 0.64527961]],
[[-1.50320008, 0.95431136, 0.04188658],
[-0.29214501, -0.70826626, 0.3320706 ],
[ 0.24138366, 0.29242283, -0.72881981]],
[[-0.09376564, 0.74390959, -0.62470312],
[ 0.54789497, -0.42938586, 0.53608342],
[ 0.74456327, 0.84202663, 0.14757674]]])
Create an array of 20 linearly spaced numbers between 1 and 10.
Show code cell content
np.linspace(1, 10, 20)
array([ 1. , 1.47368421, 1.94736842, 2.42105263, 2.89473684,
3.36842105, 3.84210526, 4.31578947, 4.78947368, 5.26315789,
5.73684211, 6.21052632, 6.68421053, 7.15789474, 7.63157895,
8.10526316, 8.57894737, 9.05263158, 9.52631579, 10. ])
Below I’ve defined an array of shape 4 x 4. Use indexing to produce the given outputs.
Show code cell content
a = np.arange(1, 26).reshape(5, -1)
a
array([[ 1, 2, 3, 4, 5],
[ 6, 7, 8, 9, 10],
[11, 12, 13, 14, 15],
[16, 17, 18, 19, 20],
[21, 22, 23, 24, 25]])
Show code cell content
a[1:, 3:]
array([[ 9, 10],
[14, 15],
[19, 20],
[24, 25]])
array([[ 9, 10],
[14, 15],
[19, 20],
[24, 25]])
Show code cell content
a[1]
array([ 6, 7, 8, 9, 10])
array([ 6, 7, 8, 9, 10])
Show code cell content
a[2:4]
array([[11, 12, 13, 14, 15],
[16, 17, 18, 19, 20]])
array([[11, 12, 13, 14, 15],
[16, 17, 18, 19, 20]])
Show code cell content
a[1:3, 2:4]
array([[ 8, 9],
[13, 14]])
array([[ 8, 9],
[13, 14]])
Calculate the sum of all the numbers in a.
Show code cell content
a.sum()
np.int64(325)
Calculate the sum of each row in a.
Show code cell content
a.sum(axis=1)
array([ 15, 40, 65, 90, 115])
Show code cell content
a.sum(axis=0)
array([55, 60, 65, 70, 75])
Extract all values of a greater than the mean of a (hint: use a boolean mask).
Show code cell content
a[a > a.mean()]
array([14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25])